Git for IT Professionals: Life Cycle of Repository Files
 Ravikanth C
Ravikanth C- 6 Min To Read
- 27 Jul, 2015
- Comments
In this series so far,
Part 1 - Git for IT Professionals: Getting Started
Part 2 – Git for IT Professionals: Working with Repositories
Part 3 – Git for IT Professionals: Life Cycle of Repository Files (this article)
In the previous part, we walked-through creating our first repository and adding files to it and finally committing the files to the repository. This was a simple and basic workflow to get started with Git. In the process, I had mentioned about tracked and untracked files and staged and unstaged files and so on. For a beginner, it is important to understand the life cycle of version-controlled files in a Git repository. This is what we will discuss in this part of the series. Similar to the other part of the series, we will use an example walk-thorough to understand the concepts. I recommend trying out the commands as you read the article.
For this article, we will start by creating a new repository with no files in it.
| |
This initializes an empty Git repository under the home directory of the logged in user. Running git status inside the repository reveals that there are no files that are tracked.
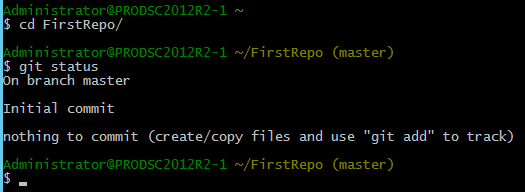
Let us add a few files here. PowerShell scripts, of course. I chose to copy a few readymade scripts I have into this repository directory directly.
Running git status now shows that I have some files that are in the repository directory or the working tree but are untracked.
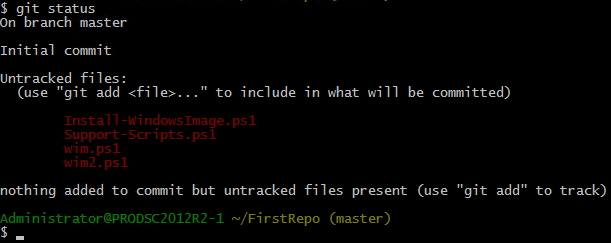
So, that first state of files in a newly created Git repository is Untracked. Git is helpful enough and tells us what needs to be done to start tracking these files. We have to run git add.
Tip: You can use git add . if you intend to add all files in the working tree to the index for next commit. I have highlighted part of the earlier sentence to ensure you understand the importance of this command. If you don’t intend to add all files in the working tree to next commit, specify them explicitly.
In my example, I am going to add all the files in the repository folder to the next commit.
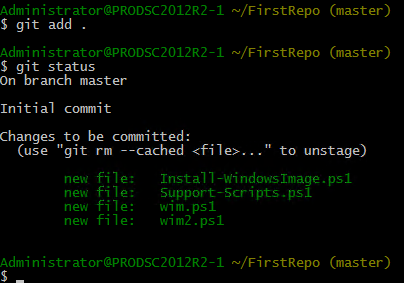
As you see in this output the files moved from Untracked to Staged! Now, if we use the git commit command, all these files will get added to the master branch and get tracked.
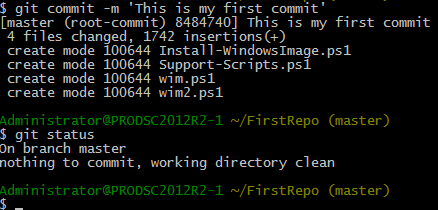
Let us now modify one of the scripts and see what happens. In my example, I modified the wim.ps1 script to add a comment at the beginning of the file.
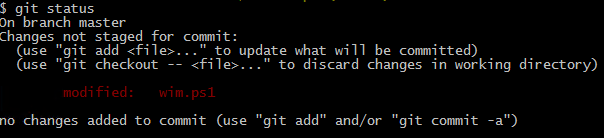
As expected, we see the file that we modified as modified! Hurray! This happens because the file is already present in the Git tracked files and the index. In technical terms, the last commit includes this file. So, Git finds that the file content is different from what is there in the last commit and tells us the same. If you read the message closely, it also tells us that we can either use git add to stage this file for next commit or git commit to commit the changes directly. For now, let us stage the changes for next commit.
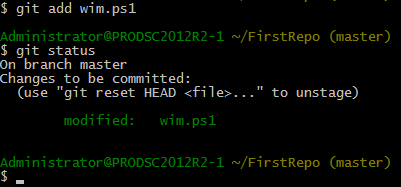
Instead of doing a commit now, let us modify this file (wim.ps1) again and check git status.
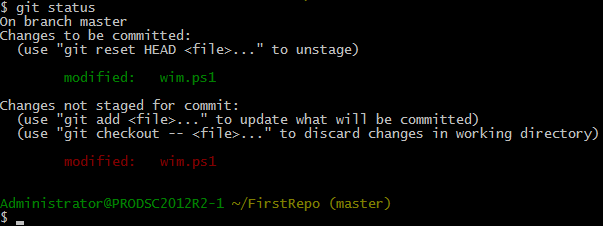
Unexpected? Not really. I said Git is different from other VCS. Git does not track changes to files per se. If we go revisit Git basics, we discussed that every time we run git add, Git actually takes a point-in-time snapshot of the file and tracks that for the next commit. So, when we modified the file again after git add, Git finds that the content of the file on disk is different from what is being tracked for next commit. This is the reason why we see the same file in the staged section as well as unstaged section of git status. If we use git commit now, the version of the file which is in the snapshot becomes tracked.
Caution: Git tells us that we can use git checkout to discard changes. Be very careful when you do this. This command takes the last staged/commit version from the repository and overwrites that on the disk. This may have unintended consequences or result in loss of data.
So, instead of discarding changes on the disk, if you want to update the staged version of the file, we can use git add –u or simply git add. The git add –u commands ensure that it updates only the modified files in staged snapshot and does not add any new files in the working tree that are not tracked yet.
While you were busy reading through and practicing what you just learned, I went ahead and made a few random changes to already tracked files, added a few more files and modified a few staged files. Here is how my git status looks like now.
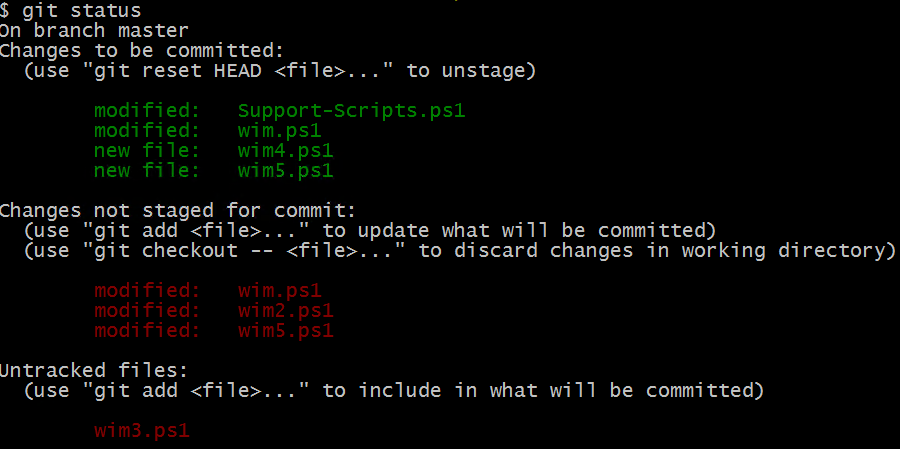
This may be confusing when more than one file is listed in different states. Git provides a short status too that can be very helpful understanding in an easy manner than a more verbose output.
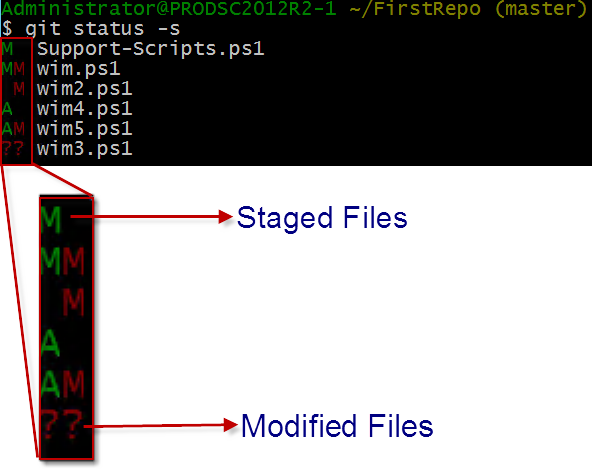
You will see that there are two columns in the output shown by git status –s. The left column indicates that the files are staged and the right-hand column indicates the files that are modified.
- The ?? at the end indicates that the file is not tracked.
- The status A shown next to wim4.ps1 and wim5.ps1 indicates that these files are new and staged for next commit.
- The status M next to newly added wim5.ps1 indicates that the file was modified after it was staged.
- The status M next to Support-Scripts.ps1 indicates that the file is modified and the same has been staged for commit.
- The status M next to wim2.ps1 indicates that the file was modified but the contents are not staged for next commit yet.
- The status MM next to wim.ps1 indicates that the already tracked file was modified and staged for next commit but was modified again.
Just remember that the left column indicates files that are staged for next commit and the right column indicates files that are modified. As you start using Git more and more, looking at this short status and making sense of what’s going on in the repository becomes very easy. Finally, what if we want to stop tracking a file in the repository? Or in other words, how do we mark a file untracked and remove it from the commit snapshot? The git rm command is the answer. Note that using git rm, removes the file from disk too. If you don’t intend to remove the file from disk, use the –Cached switch with the git rm command. However, doing so will show the removed file as untracked in the git status output.
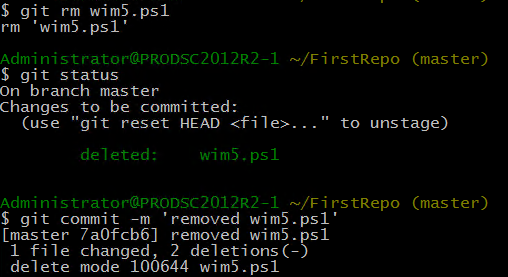
Overall, we have seen files moving from one state to another as we made changes or added new files to repository. In a nutshell, we had untracked file which moved to staged and then tracked state after a git commit. We now have the same file in staged as well as unstaged state. We finally, removed files from the repository and made them untracked again. And, that is the complete life cycle of files in a Git repository. A picture is worth a thousand words. Let us conclude today’s article by looking at this diagram that shows different states of files in a Git repository and what actions bring files to those states.
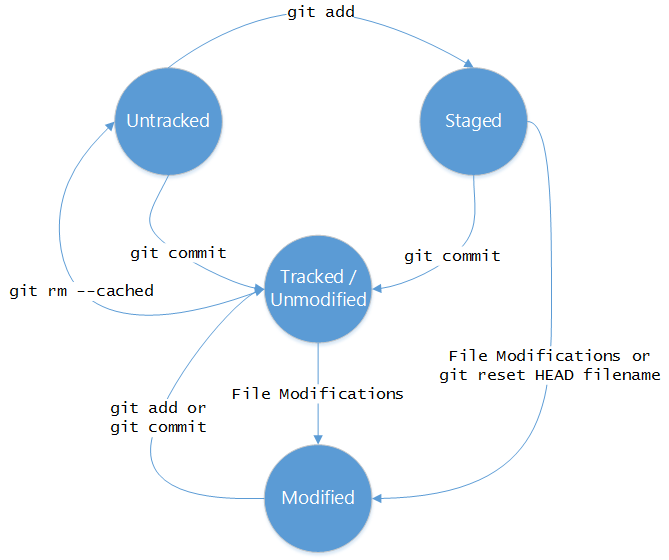
This is it for today! Your feedback is more than welcome and will help me improve the overall series. Stay tuned for more!
Share on: